
Die Neuronen in neuronalen Netzen verstehen Teil 2: Logische Neuronen
über
Im ersten Teil dieser Artikelserie haben wir erfahren, wie Forscher sich langsam der Funktionalität des Neurons angenähert haben. Der wirkliche Durchbruch bei künstlichen Neuronen kam mit dem mehrschichtigen Perzeptron (MLP) und der Verwendung der Backpropagation, um ihm beizubringen, wie man Eingaben klassifiziert. Anhand einer selbst erstellten Implementierung eines MLP in Processing haben wir außerdem gezeigt, wie es funktioniert und seine Gewichte zum Lernen anpasst. Nun greifen wir auf die Experimente der Vergangenheit zurück, um unserem neuronalen Netz beizubringen, wie Logikgatter funktionieren und prüfen, ob unser MLP in der Lage ist, die XOR-Funktion zu lernen.
Wir haben eine flexible Neural-Klasse zur Implementierung eines MLP, die in ein Processing-Projekt eingebunden werden kann. Aber die bisherigen Beispiele bestätigen lediglich die korrekte Berechnung des Vorwärtsdurchlaufs und wie die Backpropagation die Gewichte des Netzwerks anpasst, um eine bestimmte Aufgabe zu erlernen.
Nun können wir dieses Wissen an einer echten Aufgabe erproben, die schon in frühen Betrachtungen der McCulloch-Pitts Threshold Logic Units (TLU) gestellt wurde: die Implementierung von Logik. Wie wir bereits festgestellt haben, sollte unser MLP linear trennbare Probleme wie UND und ODER mit Leichtigkeit lösen. Aber es sollte auch in der Lage sein, die XOR-Funktion zu lösen, etwas, was die TLU und andere frühe künstliche Neuronen nicht konnten. Wir werden wir auch untersuchen, wie diese Netzwerke dank einer visuellen Implementierung des neuronalen Netzwerks lernen und welche Auswirkung die gewählte Lernrate auf den Ausgabefehler hat.
UND
Ein neuronales Netzwerk kann zwar lernen, die UND-Verknüpfung nachzubilden, aber es funktioniert nicht auf dieselbe Weise. Wir wenden statt dessen Eingaben in ein Netzwerk an, das die UND-Funktion gelernt hat, und fragen es: „Wie sicher bist du, dass diese Eingabekombination das Muster ist, dem wir eine 1 zuschreiben?“ Das Beispielprojekt im GitHub-Repository im Ordner /processing/and/and.pde demonstriert dies, wenn es mit Processing geöffnet wurde.
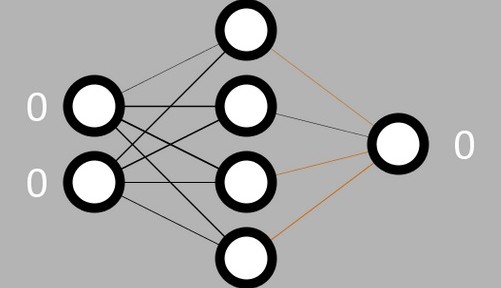
Unser neuronales Netzwerk hat wie ein UND-Gatter zwei Eingänge und einen Ausgang. Zwischen den Eingangs- und dem Ausgangsknoten sind vier versteckte Knoten (Bild 1). Wie man die Anzahl der benötigten versteckten Knoten bestimmt, werden wir später besprechen. Der Code zur Vorbereitung des Netzes ist in Listing 1 dargestellt.

Das Netz soll so trainiert werden, dass es das Muster „11“ an den Eingängen erkennt. Außerdem wollen wir sicherstellen, dass die Alternativen „00“, „01“ und „10“ die Klassifizierungsschwelle nicht überschreiten. Beim Training des Netzwerks werden die Eingangswerte und erwarteten Ergebnisse aus Tabelle 1 angewendet.
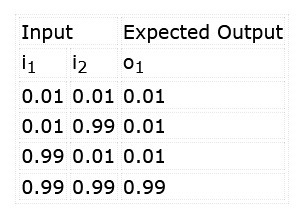
Beachten Sie, dass solche Netze nicht mit logischen, sondern mit dezimalen Werten arbeiten. Eine „1“ entspricht hier 0,99 (fast 1), eine 0 dem Dezimalwert 0,01 (fast 0). Die Ausgabe wird dann ebenfalls zwischen 0,0 und 1,0 liegen. Das Ergenis sollte deshalb auch als Zuverlässigkeit betrachtet werden, dass die Eingaben mit der gelernten Klassifizierung übereinstimmen, zum Beispiel 96,7 % Wahrscheinlichkeit, dass beide Eingaben „1“ sind. Das entspricht nicht der eindeutige 0/1-Ausgabe eines echten UND-Gatters!
Wir können den Lernerfolg des neu erstellten Netzwerks überprüfen, indem wir ihm einige Eingabewerte übergeben und die Ausgabe abfragen. Da der Konstruktor den Gewichtungen Zufallswerte zuweist, dürften sich erzeugten Ergebnisse jedes Mal unterscheiden.
Der folgende Code gibt die Ausgabe des Netzwerks auf die Eingangswerte „11“ und „00“ aus. Es ist sehr wahrscheinlich, dass das Ergebnis für „11“ nahe bei 0,99 liegt, während das Ergebnis für „00“ viel größer als die erhofften 0,01 sein dürfte:
// Check output of AND function for 00 input
network.setInputNode(0, 0.01);
network.setInputNode(1, 0.01);
network.calculateOutput();
println(“For 00 input, output is: ”, network.getOutputNode(0));
// Check output of AND function for 11 input
network.setInputNode(0, 0.99);
network.setInputNode(1, 0.99);
network.calculateOutput();
println(“For 11 input, output is: ”, network.getOutputNode(0));
Dies lieferte im Test folgende Ausgaben:
For 00 input, output is: 0.7490413
For 11 input, output is: 0.80063045
Wir konstatieren, dass das neuronale Netz bei 0,99 beider Eingänge denkt, dass die Eingabe „1 UND 1“ ist, und dies mit einer Zuverlässigkeit von 0,8006 oder 80,06 %. Dies ist in diesem frühen Stadium nicht schlecht. Wenn jedoch beide Eingangswerte 0,01 sind, ermittelt das neuronale Netzwerk eine Wahrscheinlichkeit von 0,7490 (74,90 %), dass die Eingabe „1 UND 1“ ist. Das ist leider etwas weit von den erhofften 0 % entfernt.
Um dem Netzwerk beizubringen, wie eine UND-Verknüpfung funktioniert, muss es trainiert werden. Dazu werden die Eingänge und der gewünschte Ausgang für alle vier Fälle (Eingänge 00, 01, 10 und 11, Ausgang 0, 0, 0 und 1) entsprechend eingestellt und nach jeder Änderung die Methode calculateOuput() mit aktiviertem „learning“ in einer Schleife aufgerufen:
while (/* learning the AND function */) {
// Learn 0 AND 0 = 0
network.setInputNode(0, 0.01);
network.setInputNode(1, 0.01);
network.setOutputNodeDesired(0, 0.01);
network.calculateOutput();
// Learn 0 AND 1 = 0 … Learn 1 AND 0 = 0
// Learn 1 AND 1 = 1
network.setInputNode(0, 0.99);
network.setInputNode(1, 0.99);
network.setOutputNodeDesired(0, 0.99);
network.calculateOutput();
}
network.turnLearningOff();
Die Entscheidung, das Training des Netzwerks zu beenden, kann auf verschiedene Weisen erfolgen. Jeder Lernzyklus wird in diesem Beispiel als eine „Epoche“ bezeichnet. Der Lernprozess kann nach einer bestimmten Anzahl von Epochen, etwa 10.000, gestoppt werden. Alternativ dazu kann auch der Ausgabefehler als Kriterium hinzugezogen werden. Sobald er beispielsweise unter 0,01 % liegt, kann das Netzwerk als genau genug angesehen werden.
Sie sollten beachten, dass ein MLP nicht immer zu dem gewünschten Ergebnis führt. Sie könnten aufgrund der gewählten Kombination von Eingangs- und Bias-Gewichtungen kein Glück haben, andererseits könnte es passieren, dass die Konfiguration des MLP aufgrund von zu vielen oder zu wenigen versteckten Knoten nicht in der Lage ist, Ihre Aufgabe zu lernen. Hier gibt es keine Regeln – die geeignete Anzahl von Knoten, Eingangs- und Biasgewichtungen kann nur durch Versuch und Irrtum oder Erfahrung ermittelt werden. Für dieses Beispiel haben wir vier versteckte Knoten gewählt, da vier Eingangszustände gelernt werden müssen. Dabei bleibt es zu hoffen, dass jeder versteckte Knoten einen Zustand erlernt.
Außerdem sollte das Training stufenweise erfolgen, das heißt, der Trainingsdatensatz sollte wiederholt von Anfang bis Ende durchlaufen werden. Wenn „0 UND 0 = 0“ mehrere tausend Zyklen gelehrt wird, tendiert das Netzwerk zu diesem Ergebnis, und es wird dann fast unmöglich, die verbleibenden Eingangsdaten zu trainieren.
Da die grundlegende Implementierung nun bekannt ist, können wir uns das Beispiel, in dem das Netzwerk die UND-Funktion lernt, genauer ansehen. Zum besseren Verständnis, wie neuronale Netze lernen, wird das Netz in der Anwendung während des Lernprozesses und später im Betrieb visualisiert.
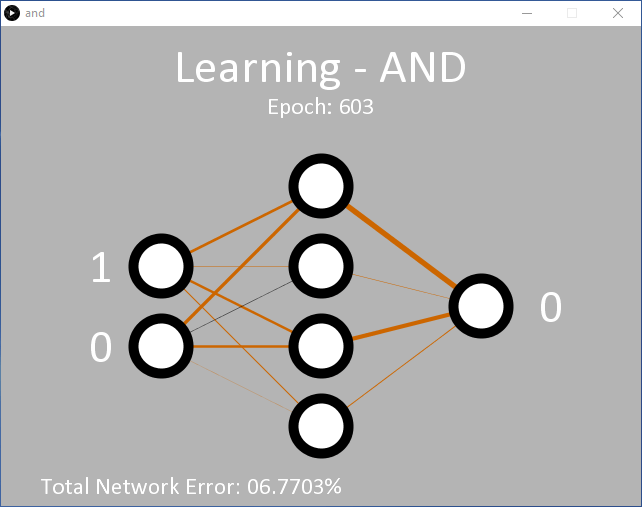
Wenn Sie auf Run klicken, sollten Sie eine Ausgabe wie im Screenshot in Bild 2 erhalten. Zu Beginn befindet sich die Anwendung im Lernmodus und bringt dem Netz die erwartete Ausgabe für eine UND-Funktion für die beiden Eingangswerte (links) bei. Während des Lernvorgangs wechseln die Eingangswerte schnell zwischen den logischen Werten 0 und 1. Auf der rechten Seite befindet sich der Ausgangsknoten, der anfangs 0 ist. Die Entscheidung, eine 1 auszugeben, wird nur dann getroffen, wenn eine Zuverlässigkeit von >90% gegeben ist, dass beide Eingänge 1 sind. Andernfalls ist der Ausgangswert 0. Diese Entscheidung wird zwischen den Zeilen 341 und 346 in and.pde getroffen.
// Output Node Text
if (network.getOutputNode(0) > 0.9) {
text("1", 550, 280);
} else {
text("0", 550, 280);
}
Anfänglich bleibt die Ausgabe 0, da die Zuverlässigkeit 90 % noch nicht erreicht hat. Nach ungefähr 5.000 Epochen sollte der Ausgabewert beginnen, zwischen 0 und 1 hin und her zu flattern, was zeigt, dass er begonnen hat, erfolgreich zu erkennen, dass die Eingangswerte 11 eine 1 ausgeben sollten. Zu diesem Zeitpunkt liegt der Gesamtfehler des Netzwerks bei etwa 0,15 %. Wenn dies nicht geschieht, ist der Lernprozess wahrscheinlich steckengeblieben.
Während des Lernprozesses werden in Processing die Gewichtungen zwischen den Knoten als Linien mit unterschiedlicher Dicke und Farbe angezeigt. Je dicker die Linie ist, desto größer ist der Wert. Schwarze Linien zeigen positive und braune Linien negative Zahlen.
Bei jeder Ausführung des Codes ändern sich die Linien, doch allmählich entwickelt sich ein Muster. Zwei versteckte Knoten haben immer eine braune und eine schwarze Linie, ein versteckter Knoten hat zwei schwarze Linien und einer hat zwei braune Linien. Die Linien zwischen den versteckten Knoten und dem Ausgangsknoten entwickeln ebenfalls ein Muster: Die einzige schwarze Linie geht von dem Knoten mit zwei eingehenden schwarzen Gewichtungslinien aus.
Dies ist eine interessante Erkenntnis, da sie zeigt, wie das Netzwerk die UND-Funktion gelernt hat. Eine 00 am Eingang lässt sich leicht in eine 0 am Ausgang überführen, ebenso eine 11 in eine 1. Für die Kombinationen 01 und 10 scheint es, dass hauptsächlich die Nullen dafür verantwortlich sind, dass die Ausgabe in Richtung 0 gedrückt wird.
Die Anwendung ist so programmiert, dass sie aufhört zu lernen, sobald in Zeile 57 von and.pde der Gesamtfehler des Netzwerks <0,05 % beträgt. Wahlweise kann der Lernvorgang auch so programmiert werden, dass er (in Zeile 55) nach einer bestimmten Anzahl von Epochen stoppt. Nach Abschluss des Lernvorgangs durchläuft die Anwendung einfach der Reihe nach die binären Eingangskombinationen, um zu zeigen, was das Netz gelernt hat (Bild 3).
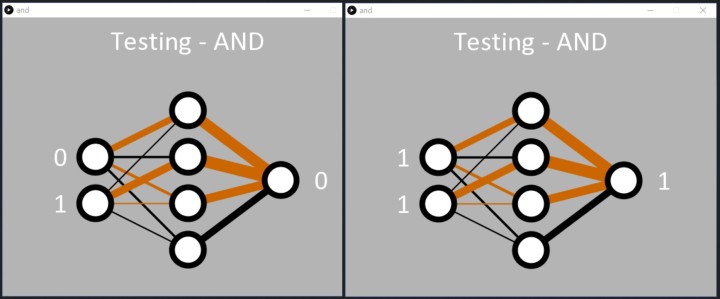
In der Textkonsole werden die Eingaben (als Dezimalwerte 0...3) mit der berechneten Ausgabe im Textformat angezeigt:
0 : 5.2220514E-4
1 : 0.038120847
2 : 0.04245576
3 : 0.94188505
0 : 5.2220514E-4
1 : 0.038120847
2 : 0.04245576
3 : 0.94188505
Für Interessenten werden der Ausgabefehler für die angewendeten Eingangswerte und der durchschnittliche Netzwerkfehler alle 50 Epochen in eine CSV-Datei namens and-error.csv geschrieben. Die Datei kann in Excel importiert werden, um zu überprüfen, wie das Netzwerk auf den Lernerfolg zustrebt (Bild 4). Die Grafik zeigt, wie der Fehler zunächst zwischen hohen und niedrigen Werten für bestimmte Eingabe/Ausgabe-Kombinationen hin und her schwankt. Der hohe Fehler liegt wahrscheinlich darin begründet, dass die Ausgabe für die Muster 00, 01 und 10 in der frühen Phase des Lernens viel zu hoch war. Der niedrige Fehler wird verursacht, wenn das Netz die Eingabe 11 schon früh korrekt auswertet.
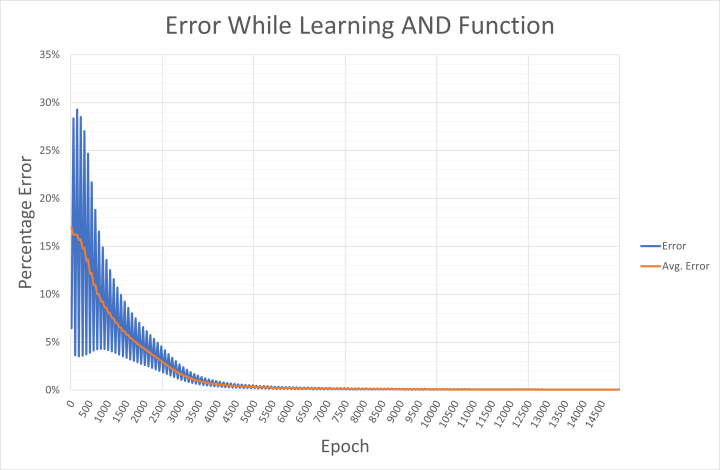
Die individuellen (momentanen) Fehler hier werden über vier Epochen gemittelt, um den durchschnittlichen Fehler zu berechnen. Sollte Ihr PC kein „Englisch“ können, müssen Sie vor dem Export in Excel mit einem Texteditor wie Notepad++ die Trennzeichen-Kommas in der CSV-Datei durch Semikolons und die Punkte durch Kommas ersetzen.
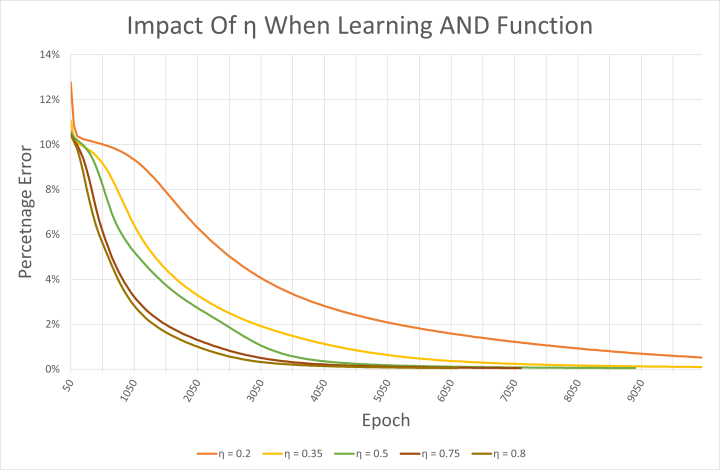
Mit der CSV-Datei kann man auch die Auswirkungen der Lernrate auf das Netzwerk zu untersuchen. Der Beispielcode verwendet eine Lernrate η von 0,5. Höhere Lernraten führen zwar dazu, dass das Netz schneller lernt, wie in Bild 5 zu sehen ist, aber es besteht auch die Gefahr von Oszillationen, so dass das Netz nie das gewünschte Lernergebnis erzielen kann. Doch alle hier getesteten Lernraten führten zu einem korrekt funktionierenden Netzwerk, das UND gelernt hatte. Es ist jedoch zu beachten, dass die Startgewichtungen jedes Mal zufällig gewählt wurden.
Kann das Netz auch XOR lernen?
Das Repository enthält in processing/or/or.pde auch Beispiele für eine ODER-Funktion. Da diese Aufgabe linear trennbar ist, hat der MLP auch keine Probleme, diese Funktion zu erlernen. Aber schauen Sie es sich ruhig den Unterschied in den Gewichtungen nach dem Lernen im Vergleich zum UND-Beispiel an!. Sowohl or.pde als auch and.pde können leicht geändert werden, um dem Netzwerk die Nicht-UND- und Nicht-ODER-Funktionen beizubringen. Der Moment der Wahrheit kommt jedoch mit der XOR-Funktion.
Ein Beispiel hierfür ist in processing/xor/xor.pde zu finden. Der Code ist ähnlich aufgebaut, und verwendet die gleiche 2/4/1-MLP-Knotenkonfiguration (Eingabe/versteckt/Ausgabe) (Bild 6). Bei der verwendeten Lernrate (η = 0,5) werden wahrscheinlich 15.000 Epochen oder mehr benötigt, bevor sich die Ausgabe zu ändern beginnt, und etwa 35.000 Epochen, bis der angestrebte durchschnittliche Fehler von 0,05 % erreicht ist.
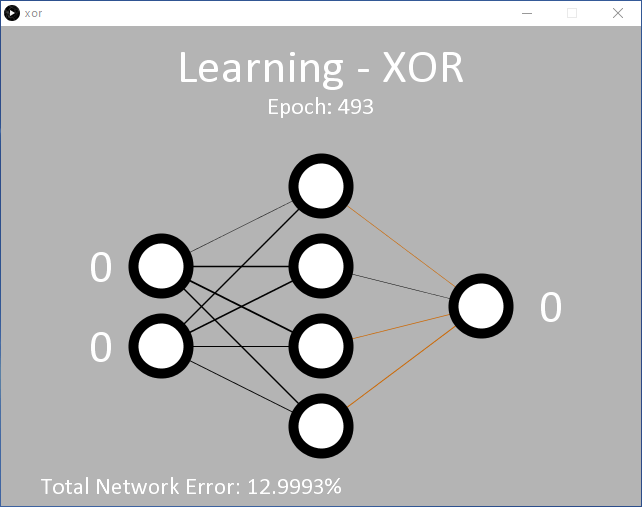
Es ist klar, dass das Netzwerk Schwierigkeiten hat, die XOR-Funktion zu erlernen. Dies spiegelt sich in den angezeigten Gewichten wider, die zwischen positiv und negativ hin und her springen, bevor sie eine Richtung wählen, und der Netzwerkfehler nimmt sehr langsam ab. Das liegt daran, dass sowohl 00 und 11 (dargestellt als 0,01/0,01 sowie 0,99/0,99 an den Eingängen) die Ausgabe 0,01 liefern sollen. Mathematisch gesehen führen Eingangswerte von 0,99 zu hohen Ausgangswerten, bis das Netzwerk in der Lage ist, das Ergebnis während des Lernens in Richtung 0,01 zu drücken. Dies ist im Ausgabefehler zu sehen, der während des Lernvorgangs in xor-error.csv gespeichert wird (Bild 7).
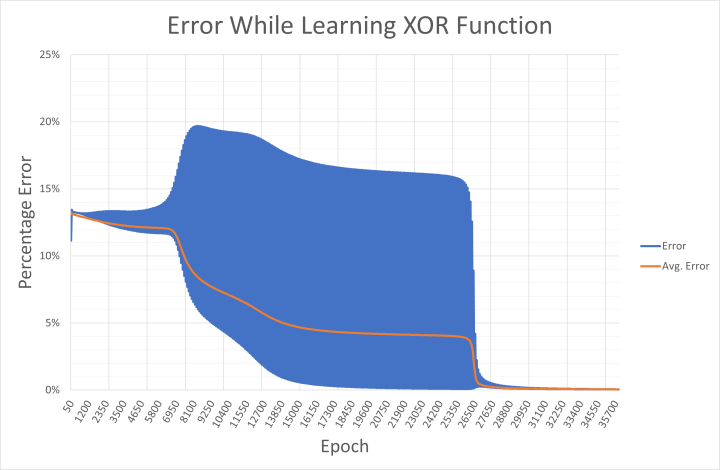
Trotz der Herausforderungen bei dieser Aufgabe erlernt das Netzwerk letztendlich die XOR-Funktion. Sobald der Fehler unter 0,05 % liegt, wendet der Code die binären Eingaben auf das Netzwerk an, und die Ausgabe reagiert, indem sie die Muster 01 und 10 korrekt erkennt. Der Code zeigt dann eine 1 am Ausgangsknoten an (Bild 8).
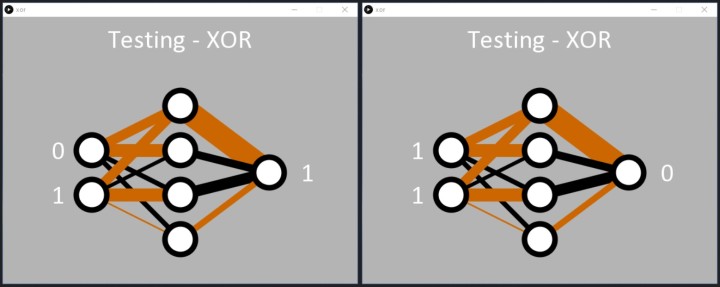
Wie beim UND-Code können wir sehen, wie das Netzwerk die XOR-Funktion gelernt hat. Zwei versteckte Knoten (die beiden mittleren in Bild 8) haben eine schwarze und eine braune Linie, die in sie hineinführen, und eine dicke schwarze Linie, die sie verlässt. Diese scheinen für die Klasifizierung von 01 und 10 verantwortlich zu sein. Das Netzwerk löste auch 00 an den Eingängen in 0 am Ausgang recht gut auf (oberer versteckter Knoten). Der Fall 11 scheint vom unteren versteckten Knoten verarbeitet zu werden, aber dies wurde möglicherweise während des Lernprozesses nicht sehr gut aufgelöst, was zu einem (noch unerwünscht) höheren Fehler führte als für die Eingabe 11 führte. Ein erneutes Ausführen des Codes würde wahrscheinlich dazu führen, dass ein versteckter Knoten offensichtlich die 11 verarbeitet und zwei schwarze Linien in einen der versteckten Knoten eintreten (Bild 9).

Beim nächsten Mal
Eines der wichtigsten Dinge, die Sie mitnehmen sollten, dürfte die Erkenntnis sein, dass es bei neuronalen Netzen keine richtige oder falsche Antwort gibt. Das Netzwerk selbst klassifiziert lediglich, wie wahrscheinlich es ist, dass die Eingaben, die Sie bereitgestellt haben, die gesuchten Eingaben sind. Wenn Sie das Netz konfiguriert und trainiert haben und es das gewünschte Ergebnis liefert, ist es wahrscheinlich richtig. Idealerweise möchten Sie dies mit einer minimalen Anzahl von Knoten erreichen, um Speicher und Rechenzeit zu sparen.
Eine Visualisierung ist zwar nett, aber nicht unbedingt notwendig. Wenn Sie daran interessiert sind, mehr herauszufinden, können Sie im Projekt processing/fsxor/fsxor.pde die CSV-Visualisierungen entfernen. Dies beschleunigt den Code erheblich. Sie können dann Ihren eigenen Code in der Klasse Neural schreiben, um Folgendes zu untersuchen:
- Welchen Einfluss hat die Lernrate auf das Netzwerk beim Lernen von XOR? Untersuchen Sie es vielleicht jedes Mal mit den gleichen Startgewichtungen.
- Können Sie die Gewichte mit Werten initialisieren, die das Netz dazu in weniger Epochen das Problem lösen zu lasen? Überprüfen Sie dies vielleicht anhand der Ausgangsgewichte aus einem früheren Durchlauf.
- Wie wenige versteckte Knoten brauchen Sie, um UND zu lernen? Und wie wenige, um XOR zu lernen? Können Sie zu viele versteckte Knoten haben?
- Ist es sinnvoll, zwei Ausgangsknoten zu haben? Einer könnte die unerwünschten Muster als 0,99 klassifizieren (für XOR 00 und 11), während der zweite die gewünschten Muster als 0,99 klassifiziert (für XOR 10 und 01).
Im nächsten Artikel über neuronale Netze werden wir das neuronale Netz darauf trainieren, Farben von einer an unseren PC angeschlossenen Webcam zu erkennen. Wenn Sie möchten, können Sie eine MLP-Knotenkonfiguration entwickeln und testen, von der Sie glauben, dass sie der Aufgabe gewachsen ist.

Haben Sie Fragen oder Kommentare ?
Haben Sie Fragen oder Kommentare zu diesem Artikel? Dann schreiben Sie bitte dem Autor eine E-Mail an stuart.cording@elektor.com.
Übersetzung: Angela | Textmaster
Diskussion (0 Kommentare)