
Neue Cache-Hierarchie steigert Leistung und senkt Energieverbrauch
10. Juli 2017
über
über
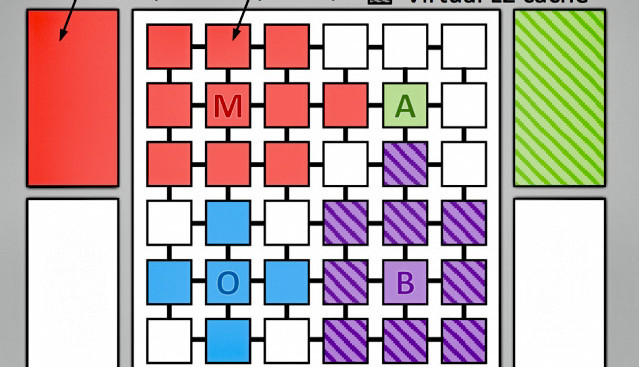
Forschern des Computer Science and Artificial Intelligence Laboratory am MIT gelang die Entwicklung eines neuen ad hoc Cache-Aufteilungsverfahrens, das bei ansonsten gleicher Hardware die Rechenleistung um bis zu 30 % steigert und den Energieverbrauch um bis zu 85 % senkt.
Schon seit Jahrzehnten wird die Rechenleistung von Prozessoren durch sogenannte Caches gesteigert, mit der die Lücke zwischen dem relativ langsamen RAM des Arbeitsspeichers und hohem Prozessortakt überbrückt wird. Ein Cache ist ein kleiner, in der Regel auf dem Die integrierter Speicher mit sehr hoher Taktfrequenz, auf den die Rechenkerne fast ungebremst zugreifen können. Schon länger haben CPUs für PCs und Laptops sogar einen kleineren 1st- und einen etwas größeren 2nd-Level Cache. Der Pentium 4 beispielsweise kam mit zwei L1-Caches mit je 8 KB und einem vorgeschalteten L2-Cache mit 256 aus. Ein aktueller i7 hingegen hat pro Rechenkern je einen 32-KB-L1-Cache getrennt für Instruktionen und Daten sowie einen zusätzlichen L2-Cache mit 256 KB mit vollem Prozessortakt plus einem für alle Cores gemeinsamen, etwas langsameren L3-Cache mit bis zu 20 MB. Um die Rechenleistung unabhängig vom Takt weiter zu steigern, werden also extreme Maßnahmen durchgeführt, die viel Platz auf dem Die kosten und damit teuer sind und den Energieverbrauch erhöhen. Man bedenke, dass vor etwas über 20 Jahren ein normaler PC weniger Hauptspeicher zur Verfügung hatte als heute eine CPU L3-Cache!
Die Forscher des MIT haben nun alternative Strategien der Beschleunigung untersucht. Hardware für die Experimente war ein Jenga-System, mit einer 36-Core-CPU mit einem konfigurierbaren L3-Cache mit der enormen Größe von 1 GB L1- und L2-Caches waren wie üblich fix den einzelnen Kernen zugeordnet. Der entscheidende Unterschied nun liegt darin, dass der L3-Cache ad hoc, d.h. während der Ausführung von Code den Code-Bedürfnissen angepasst werden konnte. Dabei kriegt dann ein Thread, der gerade ein großes Array mit z. B. 32 MB Platzbedarf bearbeitet, nicht etwa nur 1/36 des L3-Cache zugewiesen, sondern so viel, wie gerade nötig. Das unnötige zwei- oder mehrstufige Vorgehen bei der fixen Zuteilung wird so mitsamt der unnötigen Datenschaufelei vermieden. Resultat ist nicht nur eine Steigerung der Code-Ausführung um 20 bis 30 %, sondern auch eine Energieeinsparung von 20 bis 85 %, da ja unnötige interne Operationen deutlich reduziert werden.
Das genaue Verfahren kann man in Form dieses Papers als PDF herunterladen.
Schon seit Jahrzehnten wird die Rechenleistung von Prozessoren durch sogenannte Caches gesteigert, mit der die Lücke zwischen dem relativ langsamen RAM des Arbeitsspeichers und hohem Prozessortakt überbrückt wird. Ein Cache ist ein kleiner, in der Regel auf dem Die integrierter Speicher mit sehr hoher Taktfrequenz, auf den die Rechenkerne fast ungebremst zugreifen können. Schon länger haben CPUs für PCs und Laptops sogar einen kleineren 1st- und einen etwas größeren 2nd-Level Cache. Der Pentium 4 beispielsweise kam mit zwei L1-Caches mit je 8 KB und einem vorgeschalteten L2-Cache mit 256 aus. Ein aktueller i7 hingegen hat pro Rechenkern je einen 32-KB-L1-Cache getrennt für Instruktionen und Daten sowie einen zusätzlichen L2-Cache mit 256 KB mit vollem Prozessortakt plus einem für alle Cores gemeinsamen, etwas langsameren L3-Cache mit bis zu 20 MB. Um die Rechenleistung unabhängig vom Takt weiter zu steigern, werden also extreme Maßnahmen durchgeführt, die viel Platz auf dem Die kosten und damit teuer sind und den Energieverbrauch erhöhen. Man bedenke, dass vor etwas über 20 Jahren ein normaler PC weniger Hauptspeicher zur Verfügung hatte als heute eine CPU L3-Cache!
Die Forscher des MIT haben nun alternative Strategien der Beschleunigung untersucht. Hardware für die Experimente war ein Jenga-System, mit einer 36-Core-CPU mit einem konfigurierbaren L3-Cache mit der enormen Größe von 1 GB L1- und L2-Caches waren wie üblich fix den einzelnen Kernen zugeordnet. Der entscheidende Unterschied nun liegt darin, dass der L3-Cache ad hoc, d.h. während der Ausführung von Code den Code-Bedürfnissen angepasst werden konnte. Dabei kriegt dann ein Thread, der gerade ein großes Array mit z. B. 32 MB Platzbedarf bearbeitet, nicht etwa nur 1/36 des L3-Cache zugewiesen, sondern so viel, wie gerade nötig. Das unnötige zwei- oder mehrstufige Vorgehen bei der fixen Zuteilung wird so mitsamt der unnötigen Datenschaufelei vermieden. Resultat ist nicht nur eine Steigerung der Code-Ausführung um 20 bis 30 %, sondern auch eine Energieeinsparung von 20 bis 85 %, da ja unnötige interne Operationen deutlich reduziert werden.
Das genaue Verfahren kann man in Form dieses Papers als PDF herunterladen.
Mehr anzeigen
Weniger anzeigen
Diskussion (0 Kommentare)